认识 Horizon UI · 4/17:Deployment 标签页与 BanyanDB 自观测
译自英文原文:Meet Horizon UI · 4/17: The Deployment Tab & BanyanDB Self-Observability。
这是 Meet Horizon UI 系列的第四篇。第三篇画的是服务 之间 的地图。这一篇把视角收回来,画一个集群服务 内部 的实例关系,并用它解决 SkyWalking 过去一直展示得不够清楚的对象:自己的存储引擎 BanyanDB。
Deployment 标签页:查看服务内部实例关系
服务地图回答“谁调用这个服务”。新的按 Layer 配置的 Deployment 标签页回答另一个问题:“这个 服务是怎么部署的,它自己的实例之间又是怎么通信的?”选择一个服务后,这个标签页会把它的实例画成节点,并画出实例之间的调用关系。你已经在服务地图里见过的平移/缩放画布、健康 ring 节点、边流动动画和每条调用的指标侧栏都会复用,只是作用域收缩到单个服务内部。
它不是一张普通节点图,关键在三点:
- 实例渲染成六边形,并组合成 pod。 一个 pod 的 main container 是完整六边形,sibling containers 会作为更小的六边形贴在它边上。所以主进程和 sidecar 会作为一个单元呈现,跨 pod 的 sidecar 链接也会连到它真正所属的小六边形上。
- Pod 按你选择的规则聚到带标签的分组框里。 规则可以是单个实例属性(role)、多个属性组合(比如
node_role+node_type),也可以是名称正则。这样一组混合角色节点会按角色分框展示,而不是堆成一团。 - 布局是分层的。 每个 cluster box 会按调用深度摆放 pod:source 在左,被调用对象在右,所以 upstream→downstream 链条从左到右就能看清;拖动任意 pod 后,它所属的 box 会重新流式布局,保证内容仍在分组框内。
边按 (source-role → target-role) pair 区分,所以每类链接展示自己的指标,而不是所有边共用一组指标。主指标会直接印在边上,完整指标则进入 Flows 子标签页,每种 role-pair 对应一张对齐表。它默认关闭,和服务地图一样,完全从 Layer dashboards admin → Deployment 作用域配置。
把 BanyanDB 纳入 SkyWalking 自观测
这套机制不是为了多画一种图,它首先服务于一个具体场景。SkyWalking 的原生数据库 BanyanDB 是一个集群化、按角色和 tier 组织的系统,而过去 SkyWalking 很难把它作为一个整体观测清楚。新的 BanyanDB Layer 位于 Self-Observability 下,并配合 OAP 后端 SWIP-15,把通过 BanyanDB FODC proxy 抓到的指标建模为整个部署:
- 整个 cluster 是一个 Cluster(service);
- 每个 container 是一个 Container(instance),并携带
container_namerole 和node_typetier 属性; - 每个存储 Group 是一个 endpoint。
所以其他 Layer 中通用的 Service / Instance / Endpoint 导航结构,在 BanyanDB 这里就变成 Cluster / Container / Group。基于这套模型,Deployment 标签页可以直接画出数据库集群自身。
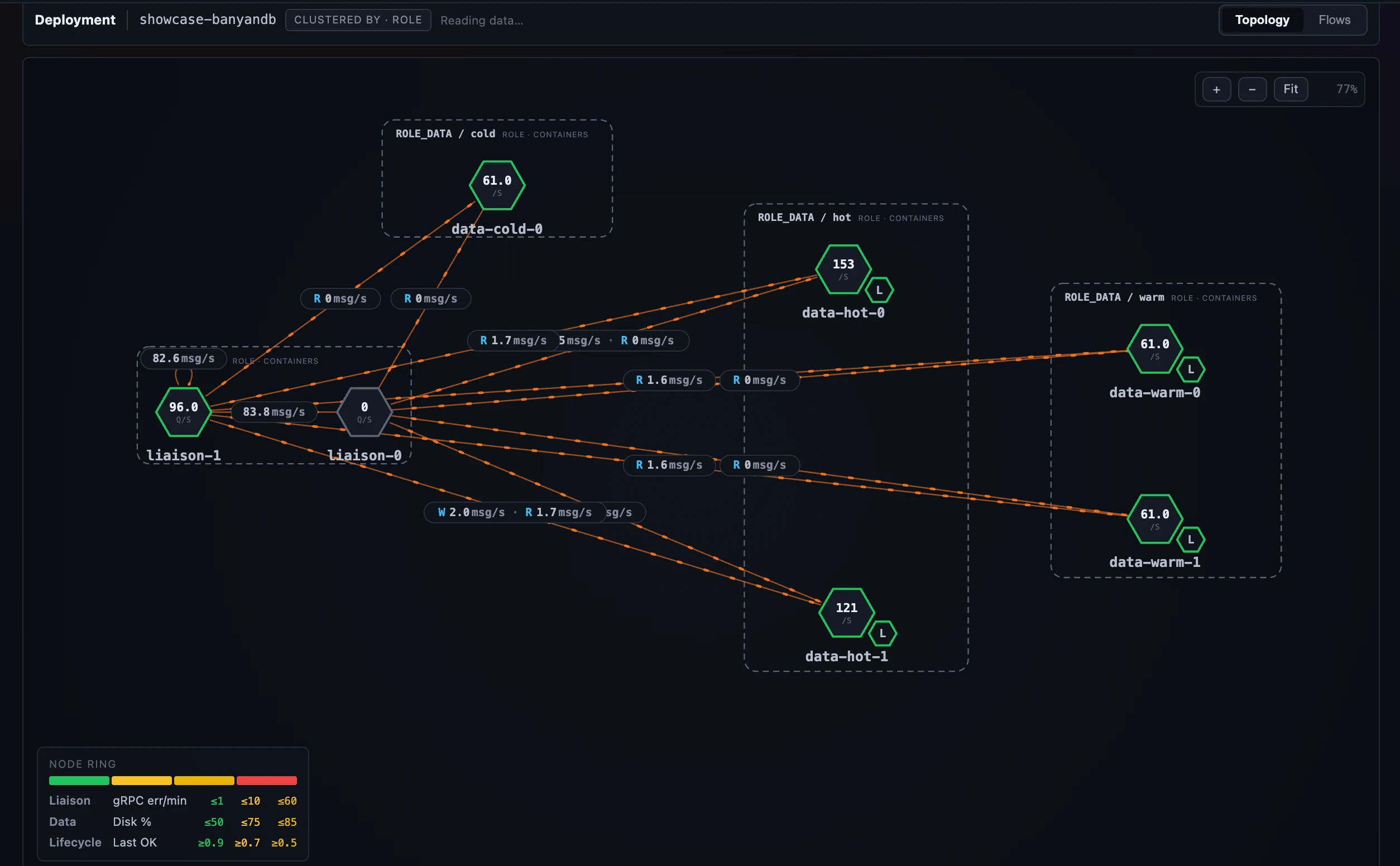 图 1:SkyWalking 观测自己的数据库:BanyanDB 集群按角色和 tier 绘制,并展示 pod 之间的 liaison→data 与 lifecycle→data 边。
图 1:SkyWalking 观测自己的数据库:BanyanDB 集群按角色和 tier 绘制,并展示 pod 之间的 liaison→data 与 lifecycle→data 边。
Cluster、Container、Group
每个作用域都有专门设计的仪表盘:
- Cluster 仪表盘是整个数据库的总览视图:write / query / error-rate KPI、CPU / memory / disk capacity、吞吐和错误趋势,以及 Containers by Role 表。
- Container 仪表盘会根据选中容器的 role 调整内容。每个容器都有 CPU / memory / Go runtime 资源面板;liaison 会增加 ingestion、query、gRPC errors、tier-2 publish pipeline 和 write-queue depth;data 节点会增加 storage totals、merge / compaction、inverted index、subscribe queue 和 retention;lifecycle sidecar 会显示 migration cycles 和 last-run time / status。角色专属面板按容器 role 属性开关,所以你只会看到当前节点适用的内容。
- Group 仪表盘按 data model 拆分:measure、stream、trace、property。因为一个 BanyanDB group 只存储一个 catalog,只有匹配该模型的面板会渲染:
measuregroup 显示 write-rate / query-latency / merge 面板,propertygroup 显示 index-write / term-search / series 面板,以此类推。
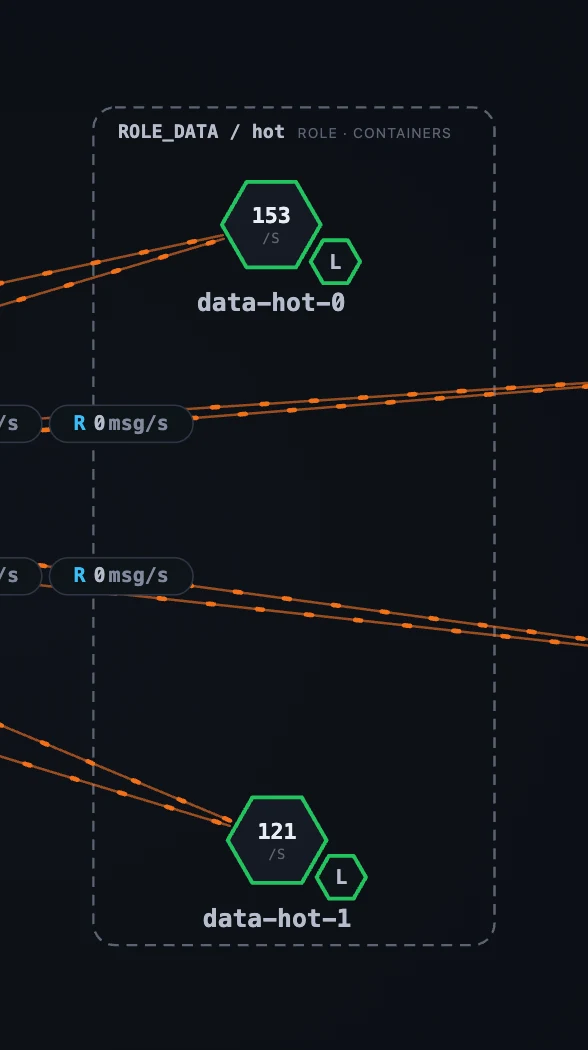
把 同一个 Container 仪表盘分别打开到两个不同 role 上,最容易看出 role-gating 的效果:
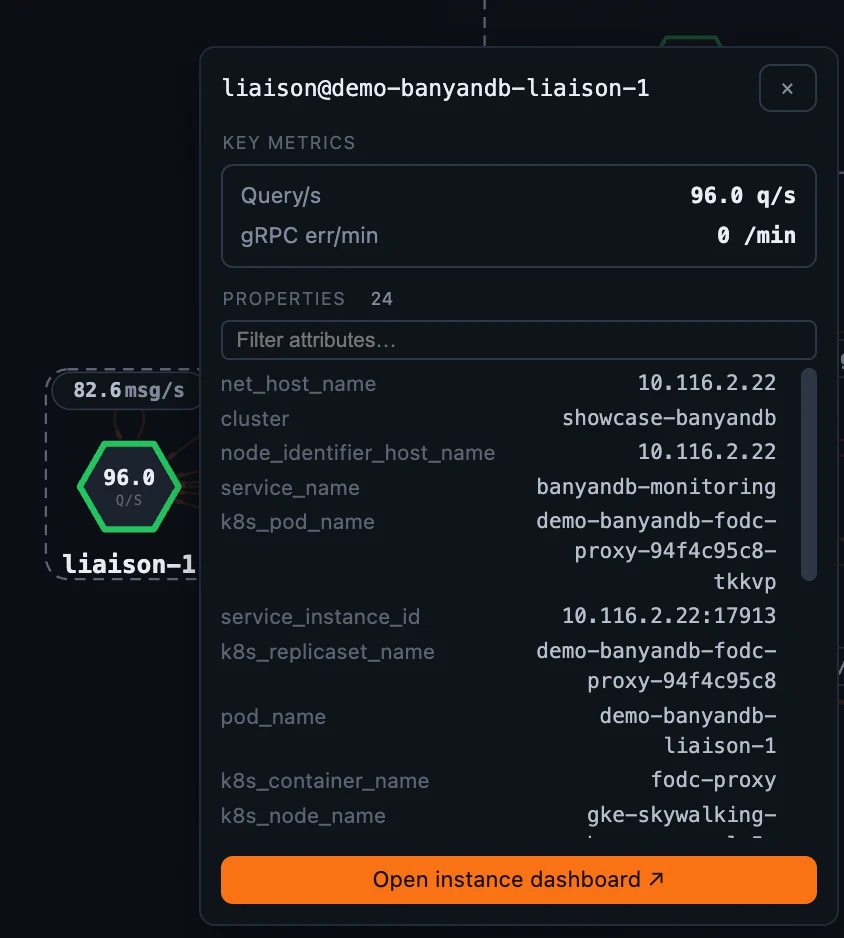
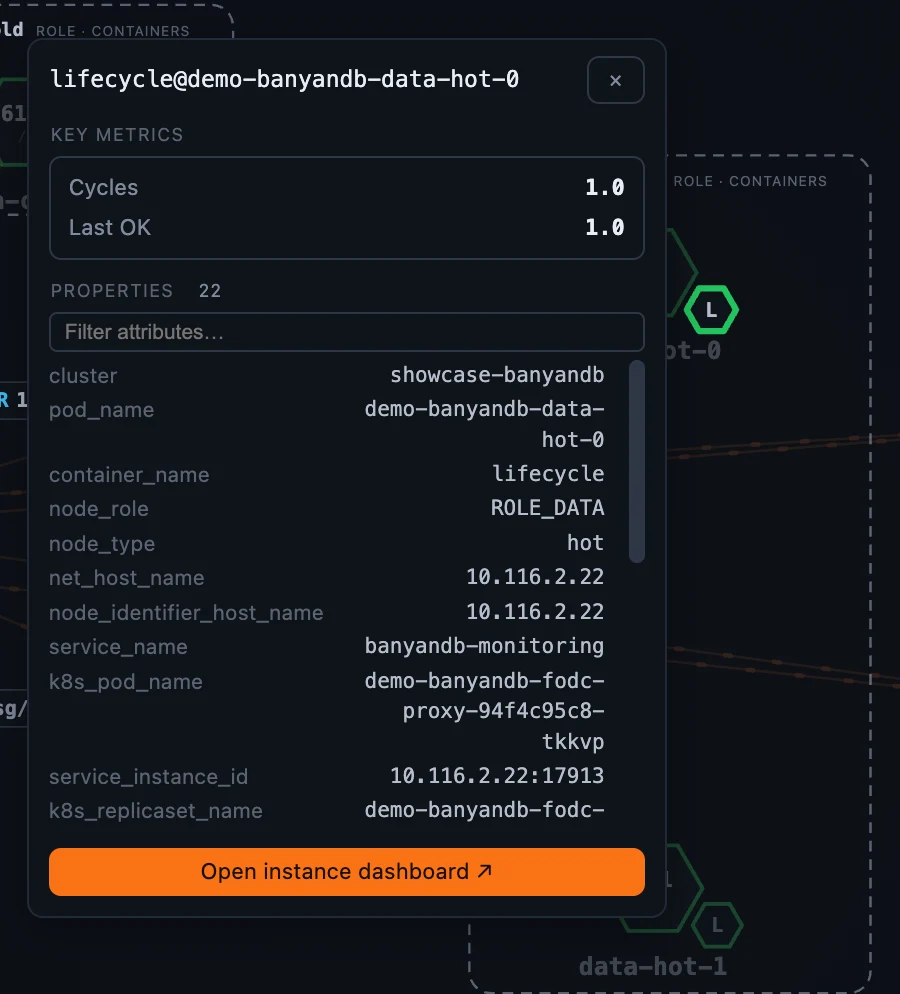
Group 作用域则让每个 storage catalog 都有独立页面:

Role pair 边与 Flows 表
Deployment 标签页中,容器之间的调用边会从 SWIP-15 instance-relation families 中拿到 role-pair-specific 指标:liaison → data 边展示 write / query / part-sync 吞吐和 p99;liaison → liaison 边展示 write-forward 和 control;lifecycle → data 边展示 tier-migration volume / rate / p99。每条边最多内联显示三项属于该 pair 的指标,选中边面板保留完整 client-vs-server 拆分,Flows 子标签页则把每条边按 role-pair 展开成一组对齐表。
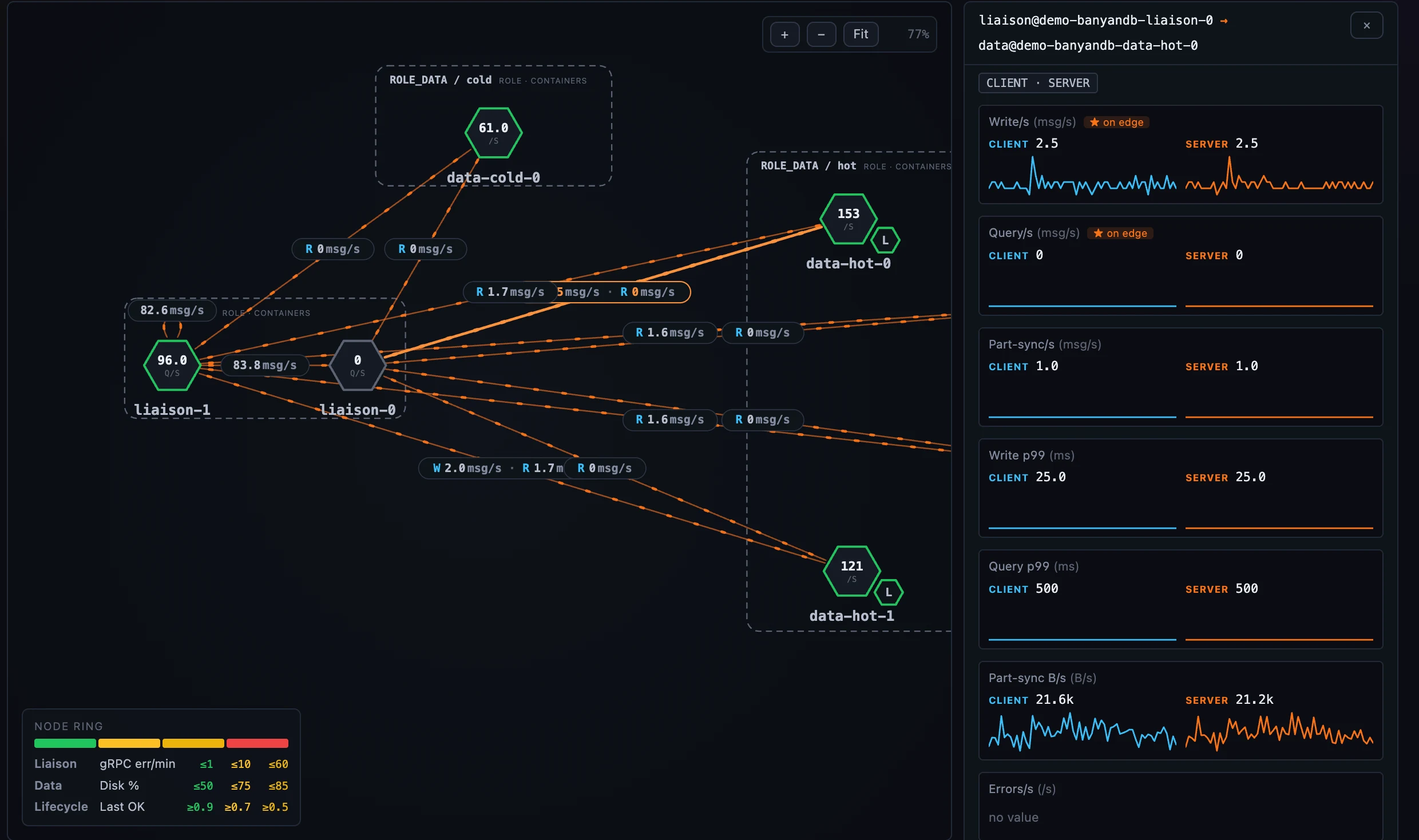 图 6:Flows,把这些 role-pair 边显示成可排序表格,每个 pair 一个区块。
图 6:Flows,把这些 role-pair 边显示成可排序表格,每个 pair 一个区块。
这里有两个前提。边和角色专属面板假设你运行的是一个真实的 集群化 BanyanDB;单进程 standalone 实例只会显示共享资源和 Go runtime 面板,其余面板会在集群角色开始上报后亮起来。尤其是 container-to-container 边,还需要 OAP 构建暴露 SERVICE_INSTANCE_RELATION 作用域;在那之前,Deployment 标签页仍然会画出完整清单,只是 pod 之间没有边。
由配置生成,而不是写死在页面里
上面这些不是一张手工写死的 “BanyanDB 页面”。聚类规则、每个 role 的节点指标、role-pair 边指标,都在 Layer template 中作为一个自包含块存在,可以从 Layer dashboards admin → Deployment 作用域编辑,并随模板 export/import 一起携带。它和其他 Layer 背后的配置驱动模型一样,后续文章会完整展开。
下一篇看 3D Infrastructure Map:把所有 Layer 的服务放进一张 WebGL 地图,从全局看部署状态。